


Souping up the Gremlin
Authors: Amit Chandak and Satish Kakollu
SailPoint’s Cloud Access Management product provides insights into the access patterns of the identities using Cloud Service Provider (AWS, Azure, Google Cloud) resources. It not only answers “who” has access to “what”, but also “how” did they get that access. In short, it creates an access graph for each identity. We use a graph database to store such connectivity. In terms of the choice for a graph database, since we wanted a vendor-agnostic approach, we decided to go with an Apache TinkerPop enabled graph database.
Scaling Gremlin Server
We had the following requirements to achieve as part of our scaling effort:
- Ingestion rate into GraphDB. This was important as we wanted to improve our graph build time, as other features within the application depended on that.
- GraphDB query times. CAM supports its own autocomplete query language, which uses gremlin as the backend query language. Since this is a user-facing feature, keeping the query time to under a second was a requirement.
- Support millions of edges and nodes in a single GraphDB instance. This requirement was stemming from how much tenant density we can support on a single gremlin instance.
NOTE: All the experimentation was done on an EC2 instance with 16 vCPUs and 64GB memory.
What is Gremlin Server?
Before understanding gremlin, let us talk about Apache TinkerPop. Quoting from the official documentation:
Apache TinkerPop™ is an open source, vendor-agnostic, graph computing framework distributed under the commercial friendly Apache2 license. When a data system is TinkerPop-enabled, its users are able to model their domain as a graph and analyze that graph using the Gremlin graph traversal language.
Gremlin is the graph traversal language for Apache TinkerPop. Gremlin Server provides a way to execute Gremlin against one or more Graph instances hosted within it.
Parametrized scripts
One of the first hurdles, we hit during the early stages of using gremlin server, was Out-of-memory (OOM). The chances of hitting OOM increased with the increase in unique gremlin queries. This discovery led us to parameterize our scripts. The gremlin documentation talks about two good reasons for doing so:
- script caching
- protection from “Gremlin injection” (same as SQL injection)
Regarding caching, since compilation of a script is “expensive”, gremlin server caches all the scripts that are passed to it after transforming them into Java code and compiling them. As you can imagine, as the number. of unique queries increased, the memory requirement for the gremlin server increased and we hit OOM. Parameterization of scripts helped us resolve the OOM issue.
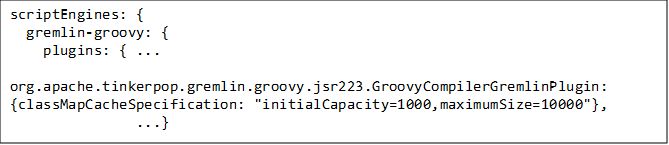
However, mere parameterization wasn’t good enough, especially with more unique queries coming in. We had to limit the cache allocated for storing these scripts, on the gremlin server side. This can be configured using GroovyCompilerGremlinPlugin in the following fashion:
Improved edge addition query
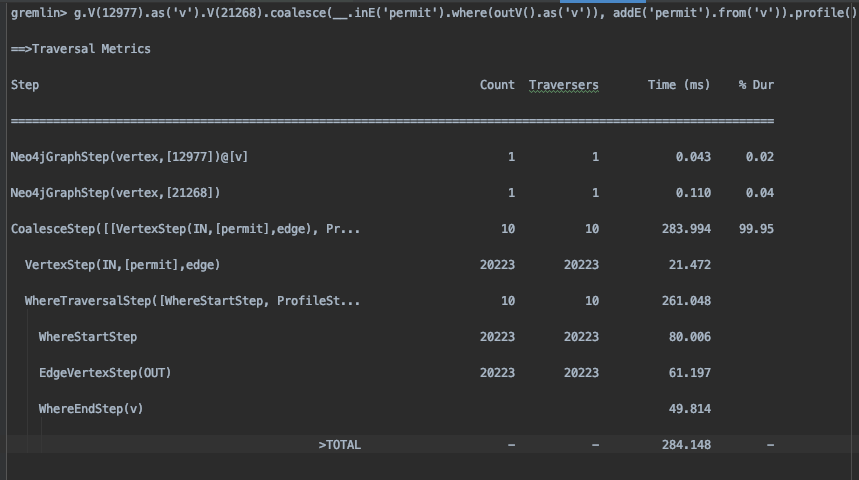
The most useful tool in analyzing the performance of gremlin queries is the profile step. Every vertex and edge in a graph has a unique ID, generated by the graph system. Using the profiler, we realized that the time taken to add an edge, when the source and destination nodes are looked up based on some unique property was slower than using the source and destination node ID.. This finding led us to cache the node ID returned from addV() call, within our application. Using the node ID, the addEdge query can be written as
gremlin> g.V(12977).as(‘v’).V(21268).coalesce(__.inE(‘permit’).where(outV().as(‘v’)),
addE(‘permit’).from(‘v’)).profile()
The above query is drawing a permit labelled edge from node ID 12977 to node ID 21268.
The above query worked well for a smaller (less than million edges) graph and also when the graph was balanced, as in each vertex had similar no. of outgoing edges. However, as the number of objects grew in comparison to the number of identities, leading to a more unbalanced graph, the query’s performance deteriorated. That’s when we modified the query to use fold(). The new query was identified as the canonical pattern for upsert, widely adopted by the community.
Here is the .profile() output of the old and new query
Old query
New query
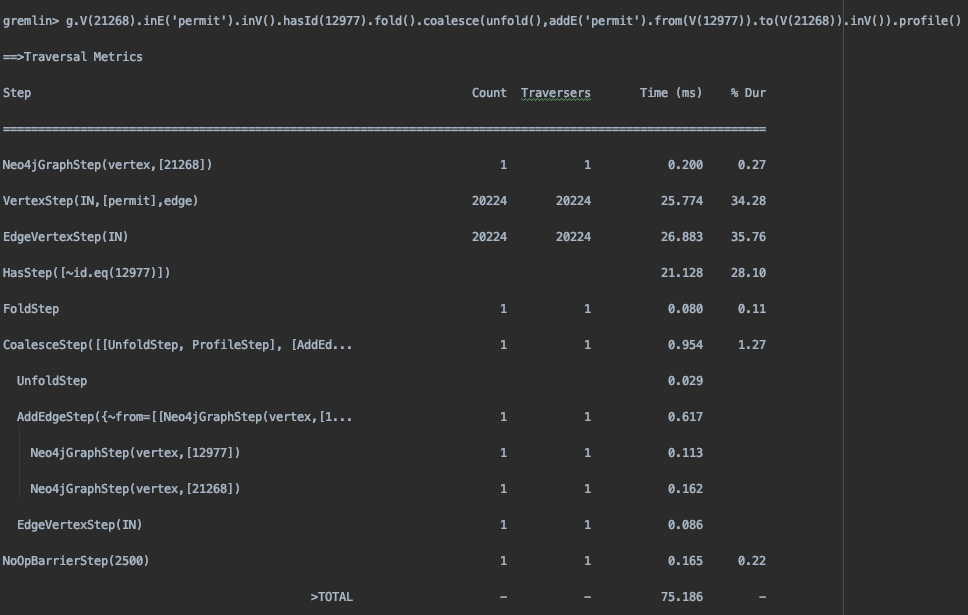
As seen from the Total time shown above, we see a huge improvement in the query time. The improvement can be attributed to significantly fewer traversals the new query does in comparison to the old one.
Improve parallelization
Assuming t being the time taken by a single edge addition query, N being the total number of edges, we were expecting the total time taken to add N edges to be approximately
Total time = (N X t)/Number of threads
This is assuming queries can be run in parallel. In our experiment, we thought we set the number of threads at 32. However, the performance we saw was way off.
Two config items, on the gremlin server side, caught our attention:
- gremlinPool – The number of “Gremlin” threads available to execute actual scripts in a ScriptEngine. This pool represents the workers available to handle blocking operations in Gremlin Server. When set to 0, Gremlin Server will use the value provided by Runtime.availableProcessors().
- threadPoolWorker – The number of threads available to Gremlin Server for processing non-blocking reads and writes.
Configuring the gremlinPool to 0 and threadPoolWorker to 2 * vCPUs, seemed like a logical starting point. The idea was for blocking operations, let gremlin server determine the number of threads and for non-blocking (which is going to be majority of the case), let the gremlin server use the maximum number of threads possible. This definitely improved the total time, though we still saw CPU spikes on the server side.
Further investigation in our code revealed that we were using a single gremlin websocket connection to send out the queries. This was potentially causing a Head-of-line blocking issue. To improve that, we created a pool of websocket connections (matching with the threadPoolWorker config) and started distributing the queries over this connection pool uniformly in a round-robin fashion.
With the above optimizations, we achieved the following:
- 5x improvement in the tenant density on a single instance.
- 7-8x improvement in the ingestion rate and query times.
As the world of graph databases is new and fast evolving, there is definitely more room for improvement. Some of the things we are looking into:
- Clustering – Clustering is the natural next-step from a single instance. Data redundancy, load balancing, high availability are some of the advantages of clustering.
- Sharding and multi-database support – Currently, all the tenants share the same graph database and we use labels() to achieve multi-tenancy. Sharing the database could be concern for some customers, so having separate databases in a single cluster would alleviate that concern.
Discussion