


Managing AWS Glue Costs and DPU Capacity with Glue Job Metrics
What is AWS Glue?
According AWS developers guide – “AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams”. AWS Glue is serverless, so there’s no infrastructure to set up or manage. For more details on AWS Glue refer to this excellent AWS Glue documentation.
What is a Glue Job?
A job is the business logic that performs the extract, transform, and load (ETL) work in AWS Glue. When you start a job, AWS Glue runs a user provided script that extracts data from sources, transforms the data, and loads it into targets.
How SailPoint leverages Glue?
We use Glue to ingest cloud activity data from a customer’s governed account for analysis in our Cloud Access Manager. The data goes through transformation and aggregation. The processed data is stored in an S3 bucket for consumption by other applications like our machine learning pipeline.
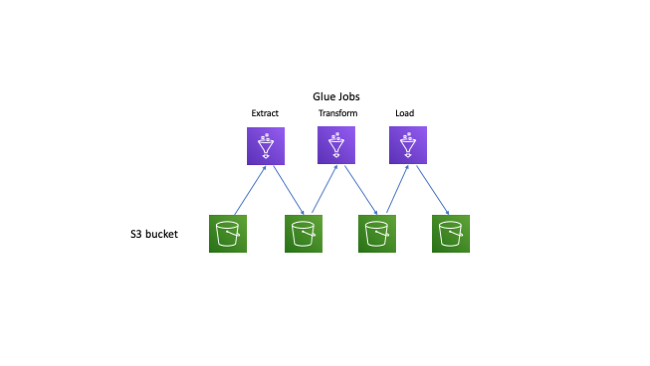
Managing AWS Glue Costs
With AWS Glue, you only pay for the time your ETL job takes to run. You are charged an hourly rate, with a minimum of 10 minutes, based on the number of Data Processing Units (or DPUs) used to run your ETL job. A single Data Processing Unit (DPU) provides 4 vCPU and 16 GB of memory. DPU is a configuration parameter that you give when you create and run a job. There are two types of jobs in AWS Glue: Apache Spark and Python shell. In this post we will focus on the Apache spark jobs.
For SailPoint’s SaaS platform, based on the amount of data we needed to process, we estimated the number of DPUs we needed to configure for the glue jobs. To monitor the cost and plan for DPU capacity in future, we enabled Glue Job metrics. We regularly monitor the job metrics to plan for Glue scale and manage the associated costs.
We have found two key areas where the job metrics have come in handy:
- Identifying any straggler tasks in the jobs. Straggler tasks take longer to complete, which delays overall execution of the job. Execution time directly impacts your glue job costs so identifying and addressing the root cause of straggling jobs can be key in savings.
- Coming up with an ideal number of DPUs for your jobs to run. If your job takes less than 10 minutes to run, you are better off using a small number of DPUs. Here is a table with cost comparison for different run times and DPU configurations:
| Number of DPUs | Cost Per Hour | Job Run Duration (minutes) | Cost Estimate – 1 Run | Cost Estimate – 5k runs |
| 2 | $0.44 | 3 | $0.15 | $733.33 |
| 10 | $0.44 | 1 | $0.73 | $3,666.67 |
| 40 | $0.44 | 1 | $2.93 | $14,666.67 |
Here is a graph comparing such a run between 2 DPUs and 10 DPUs where the additional DPUs are not being used by the job. Given the cost is higher you are better off staying with 2 DPUs:
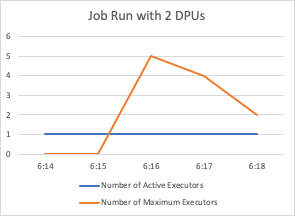
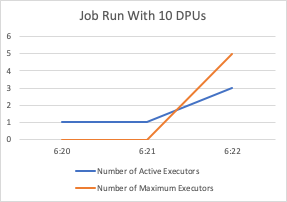
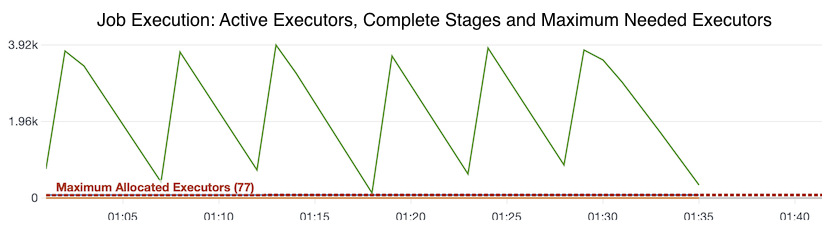
The Job Execution metric gives you a view in to coming up with the right number of DPUs.
As the scale of data grew for our customers, the first problem we hit was straggler tasks. As we onboarded a new account, we discovered that a job was taking 10+ hours to run to completion. The job was configured to run with 2 DPUs. 1 DPU was dedicated for application container and 2nd DPU was dedicated for executors. There are 2 active executors per DPU. The metric Job Execution gives a view of number of active executors at a given time, number of completed stages for a job and number of active executors.
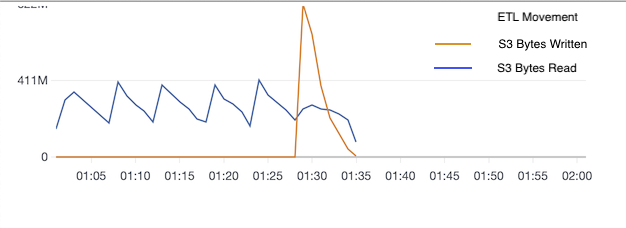
For this job we had 500,000 objects to read in our application. The total size of our data was about 1.7 GB. That is, on average each object is smaller than 4 KB. With such tiny objects, the overhead in making an HTTP request for each object was significant. HTTP request was for reading the data from S3 bucket. In estimation, if the round-trip latency to get a single object required 100 ms, then in a second you can read approximately 20 objects with 2 executors. It would require 500,000 / 20 = 25,000 seconds ~ 7 hours to finish reading all the objects and then do further processing. We increased the DPUs to 40 and job execution time reduced significantly to less than an hour. When we had 40 DPU for the job, one was the application master, which then had 78 executors. We significantly increased the parallelism of our application and can visualize it through job metrics. Figures below show five job metrics for an actual job with 40 DPUs. X-axis shows the job execution time and Y-axis shows different metrics:
- Figure 1 shows ETL data movement over time. Most of the time is still spent in reading data from S3 (about 25 minutes) but it is significantly less than 7+ hours our original configuration would have taken. Last 5 minutes shows the spike of data writes at the end.
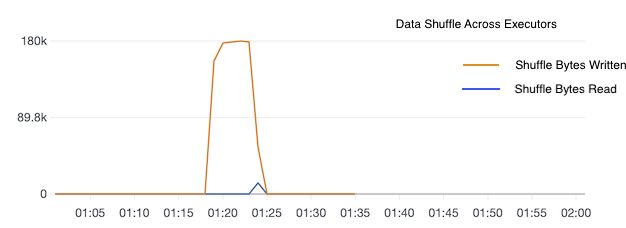
- Figure 2 is Data shuffle (a Spark intermediate step during map/reduce) across executors. The shuffle operation shows a spike for about 5 minutes.
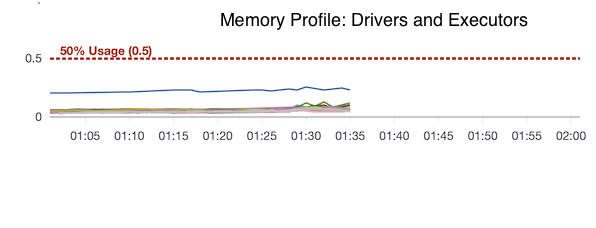
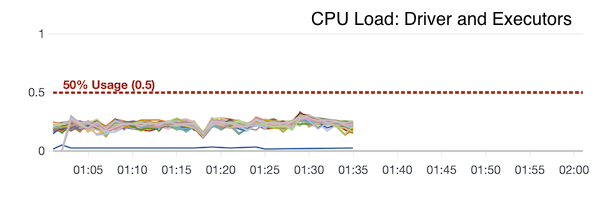
- Memory usage and CPU load across all executors is well below 50% so nothing to worry about here.
- Looking at the Job Execution metric it almost follows a sawtooth pattern for the duration of ETL data movement and maximum executors are allocated. The graph also shows number of maximum needed executors. This number can be used in determining if you need to increase DPU capacity. For us 35 minutes of job execution time was acceptable and hence 40 DPUs was a good short-term fix to bring down the job execution time.
- Next step was a long-term fix to coalesce the small files so we can go back to using 2 DPUs. Once the long-term fix was in place, we were back to using 2 DPUs with jobs taking 2 hours to run. This brought down our cost of the job from ~ $60 to ~ $11. These numbers may not seem big for a single job, but when you have many of these jobs that get run every few days, the cost can be substantial.
The second problem we saw at SailPoint appeared as the number of customers and the size of their cloud environments both grew significantly. We had a job that used to run every hour and would finish in less than 10 minutes. Remember I had talked about in the beginning that DPU charges are in increment of 10 minutes. We were running this job with 2 DPUs as the need for more DPUs was not just there. In Q1’2020 we saw a spike in the run time and some of the runs were taking 2+ hours. Having the job metrics enabled came in handy. We looked at the ETL movement metrics and the Job Execution metrics. It was clear that we were processing lot more data and Job Execution metrics gave us a recommendation on maximum needed executors. Let’s look at cost analysis in the table below along with approximate cost:
| Number of DPUs | Cost per DPU Hour | Job Run Duration (minutes) | Cost Estimate – 1 Run | Cost Estimate – 5k runs |
| 2 | $0.44 | 127 | $1.86 | $9,313.33 |
| 10 | $0.44 | 7 | $0.73 | $3,666.67 |
| 40 | $0.44 | 5 | $2.93 | $14,666.67 |
Based on this, we chose a 10 DPU configuration as best to optimize the combination of job run time and the Glue cost. As you can see from the table, in this case increasing the number of DPUs also brought our cost down.
Cloud providers are giving us great tools to work with and significantly bring down the cost and time required to setup the infrastructure. This ease does not take away the planning and monitoring that the organization leveraging this infrastructure must put in place. At SailPoint, we leverage the Glue job metrics available with AWS Glue infrastructure to monitor the current cost and scale as well as plan for growth.
References:
Discussion